Until a few years ago, deep learning was a tool that could hardly be used in real projects and only with a large budget to afford the cost of GPUs in the cloud. However, with the invention of TPU devices and the field of AI at the Edge, this completely changed and allows developers to build things using deep learning in a way that has never been done before.
In this post, we will explore the use of Coral devices, in conjunction with deep learning models to improve physical safety at one of the largest container terminals in Uruguay.
If any of this sounds interesting to you, sit back, and let’s start the journey!!
. . .
The Port of Montevideo is located in the capital city of Montevideo, on the banks of the “Río de la Plata” river. Due to its strategic location between the Atlantic Ocean and the “Uruguay” river, it is considered one of the main routes of cargo mobilization for Uruguay and MERCOSUR . Over the past decades, it has established itself as a multipurpose port handling: containers, bulk, fishing boats, cruises, passenger transport, cars, and general cargo.
MERCOSUR or officially the Southern Common Market is a commercial and political bloc established in 1991 by several South American countries.
Moreover, only two companies concentrate all-cargo operations in this port: the company of Belgian origin Katoen Natie and the Chilean and Canadian capital company Montecon. Both companies have a great commitment to innovation and the adoption of cutting-edge technology. This philosophy was precisely what led one of these companies to want to incorporate AI into their processes and that led them to us.
Motivation
The client needed a software product that would monitor security cameras in real-time, 24 hours a day. The objective was to detect and prevent potential accidents as well as alert them to the designated people. This AI supervisor would save lives by preventing workplace accidents while saving the company money in potential lawsuits.
In other words, this means real-time detection of people and vehicles doing things that can cause an accident. Until now, this was done by humans who, observing the images on the screens, manually detected these situations. But humans are not made to keep their attention on a screen for long periods, they get distracted, make mistakes and fall asleep. That is why AI is the perfect candidate for this job: it can keep its attention 24 hours a day, it never gets bored and it never stops working.
Why is safety so important? A container terminal is in constant motion where trucks and cranes move the goods demanded by the global economy. In this scenario, a fatal accident is just a tiny miscalculation away. ️. Fortunately, these accidents can be avoided by following some safety guidelines.
Time to hands-on
Many things could be monitored and controlled, seeking to reduce the probability of accidents in the terminal. However, the probability can be radically reduced by automatically running the following set of checks against security images:
- Check that every person in image is wearing their PPE (Personal Protective Equipment)
- Check that no vehicle or person is inside an area considered a prohibited area for safety reasons. For instance, the container stowage area or also the marked lanes through which an RTG crane moves. ️️
- Check that no truck, cars or small vehicles move in the wrong direction in the one-way lanes.
- Check that no vehicle exceeds the defined speed limit

Example of RTG Crane (Photo of Kuantan Port on Wikipedia)
To wrap things up, what we need is a system that can access and process the video stream of the security cameras to:
- Detect objects of interest (e.g. vehicles, pedestrians).
- Look for violations to this set of rules.
The diagram below illustrates better the mentioned pipeline.
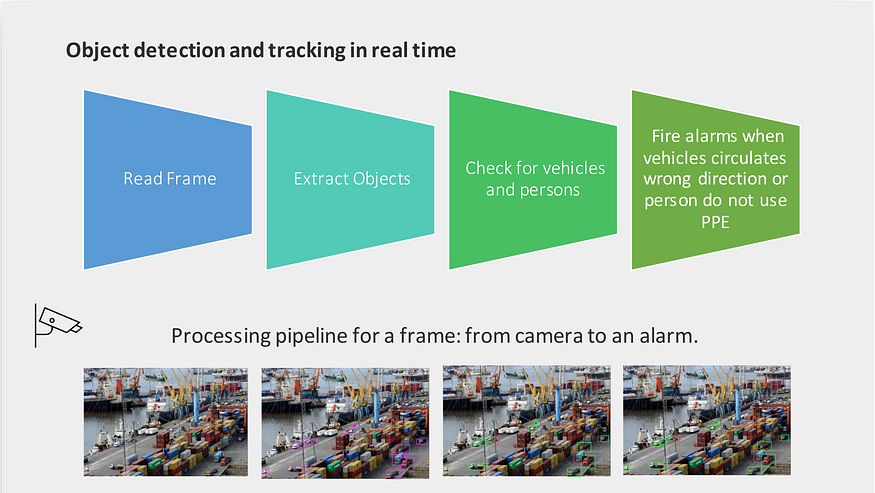
Solution diagram by IDATHA
Accessing video camera stream, can be done using Python and video processing libraries, easy-peasy. Detecting pedestrians and vehicles and then checking moving directions to finally evaluate an in/out zone rule is more challenging. This can be done using Deep Learning models and Computer Vision techniques.
Accessing video camera stream
IP cameras use a video transmission protocol called RTSP. This protocol has a very convenient particularity: save the bandwidth consumption by transmitting an entire video frame only every certain number of frames. In between, it sends the pixel variations of the previous video frame.
There are some RTSP clients available on the internet which allow you to consume the video stream from an IP camera. We use the client provided by the OpenCV library, implemented in the cv2.VideoCapture class.
Object detection and PPE classification
There are plenty of pre-trained models to detect objects, each with a different trade-off between model accuracy and hardware requirements, as well as execution time. In this project, we had to prioritize performance in detection over hardware requirements because security cameras were far away from the action, making pedestrians and vehicles look too tiny for some models to detect them.
After several performance tests on real images, the winning object detection model was Faster R-CNN, with moderate-high CPU usage, and an average inference time of 500 ms on a cloud-optimized CPU VM (Azure Fsv2 series).
In the case of the PPE classifier there are also several implementations options. In our case we decided to do a Transfer Learning on the Inception model over real images. This approach proved to be very precise and at the same time CPU efficient.
Why not zoom in? Security cameras are part of a closed circuit used by different areas at the company, mainly for surveillance purposes. Consequently, reorienting a camera or zoom was absolutely off the table.
Object Tracking and check safety rules
After calling the Object Detection model, the positions of objects (pedestrians, trucks, etc.) can be compared with the coordinates of the prohibited areas (for example, the container stowage area) and checked if any of them violate any rule. However, a piece of the puzzle is still missing: a method to track the same recognized object over time (consecutive frames in stream).
With a method like this, a pedestrian inside a prohibited area can be detected when he enters, then tracked until he leaves, triggering a one-time alert. There are several models and methods to address this problem, also known as Object Tracking. We used Centroid Tracker algorithm as it showed the best test results.
Framework selection (spoiler alert: it is TensorFlow)
As with pre-trained models, there are several frameworks for working with deep learning; two of the best known and most mature are PyTorch and TensorFlow. In particular, we chose TensorFlow for the following reasons:
- Maturity of the suite.
- Tensorflow Optimization Toolkit, which helps reducing memory and CPU usage.
- Native support for Coral TPU devices.
However, this doesn’t mean that PyTorch would have been a bad choice. We would have changed the hardware option, since PyTorch doesn’t support Coral, but we could have tested it on the NVIDIA Jetson Nano device.
Coral vs. Cloud vs. Servers: the scale factor story
For the sake of an early production release, the first deployment used GPUs servers in the cloud. More in detail, an Azure NC6 VM was used (read more about NC series here). According to the official documentation, this VM has 1 virtual GPU = half NVIDIA TESLA K80 card.
Initially, the hardware was sufficient to process the images from the first 2 cameras. However, time revealed two limitations of this deployment:
- Processing the images in the cloud, saturated the terminal network bandwidth with the video uploading.
- More important, the solution scale factor was 1 NC6 VM (1 virtual GPU) for every 4 new cameras.
This scenario is where Coral (Google’s TPU devices) kicked the board.
With an initial investment of around USD 100 and no monthly costs, these devices can be installed in the terminal without consuming network upload bandwidth. Also, by optimizing detection models for TPU, using TensorFlow Lite, inference times are reduced around 10x. In this way, the scaling factor changes to a new Coral device every 10 new cameras approximately.
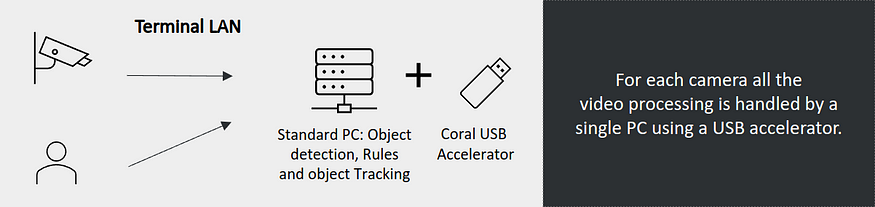
Deployment using Coral by IDATHA
Quick recap!
Let’s quickly summarize all the things we have mentioned about the problem and the solution :
- Safety is enhanced by automatically analyzing frames against object rules.
- Video stream images are accessed through RTSPusing OpenCV library.
- Pedestrians, trucks among others are detected using Faster R-CNN
- Mandatory use of PPE is checked using an image classifier model based on Inception.
- Centroid Trackeralgorithm is used to track objects throw time in video.
- Coraltogether with TensorFlow Lite allows running the model with high performance in situ.
Conclusions
Based on the results obtained by the models, performing the observation and surveillance tasks, we can affirm that the solution is a huge success:
- The models used in this project can perform the same tasks previously performed by security guards, with a higher level of reliability, all day long, maintaining the same performance and no rests.
- More central, surveillance is tedious, monotonous, and could have a detrimental effect on health. Relieving the security guards in these specific tasks, we free them to focus on more challenging labors that require higher skills and cannot be carried out by machines.
- Advances in the field of AI at the Edge, and in particular Coral devices, allow us to develop a low-cost solution. According to our calculations for this project, cloud-based solutions are at least 7x more expensive than Coral.
Undoubtedly there are working lines that weren’t explored that can potentially improve the solution in both performance and operational costs
— but you know who I think could handle a problem like that: future Ted and future Marshall —